Introductie
Om de mate van risicovermindering bij diversificatie te kunnen meten, introduceren we het begrip 'covariantie'. We zagen dat
de variantie en de standaarddeviatie maatstaven zijn voor de mate van spreiding van de waarnemingen binnen één populatie van
waarnemingen. De covariantie meet de samenhang van de afwijkingen in twee waarnemingspopulaties X en Y door middel van de
volgende vergelijking:
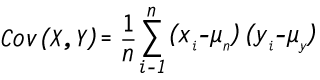
waarbij Xi staat voor de verschillende individuele waarnemingen in de populatie X, en Yi in de populatie Y. De variabelen μx en μy staan voor het rekenkundig gemiddelde van de populaties X en Y. De parameter n ten slotte geeft de omvang van het aantal waarnemingen in de populaties X en Y weer.
In Excel kunnen we met behulp van de functie COVARIANTIE(matrix1;matrix2) de covariantie berekenen van twee gegevensbereiken in de vorm van twee matrices.
Doel van deze tool
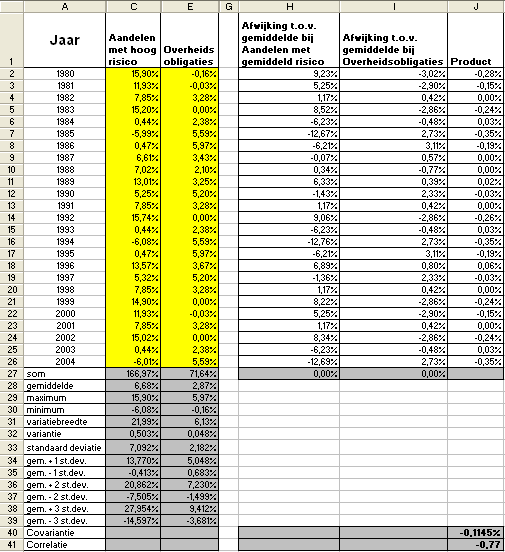
In het werkblad Berekening covariantie voor de aandelen met hoog risico en overheidsobligaties hebben we – op basis van het
werkblad Rendement en risico van diverse beleggingen – de covariantie berekend voor de categorieën 'Aandelen met hoog risico' (kolom C) en 'Overheidsobligaties' (kolom E). Daarbij zijn we als volgt te werk gegaan:
- In kolom H hebben we de verschillen opgenomen van de individuele waarnemingen ten opzichte van het gemiddeld rendement (C28) voor de categorie 'Aandelen met een hoog risico'.
- In kolom I hebben we de verschillen opgenomen van de individuele waarnemingen ten opzichte van het gemiddeld rendement (E28) voor de categorie 'Overheidsobligaties'.
- In cel J40 hebben we de covariantie bepaald door invulling van de Excel-functie COVARIANTIE(H2:H26; I2:I26) = -0,1145%.
De gevonden uitkomst voor de covariantie is ook handmatig te verkrijgen door – conform de onderliggende vergelijking – de
som van de productkolom J (cel J27: -2,86%) te delen door het aantal waarnemingen (25).
De covariantie geeft een negatieve uitkomst te zien, wat aangeeft dat sprake is van een negatieve relatie tussen de rendementen
van de categorieën 'Aandelen met een hoog risico' en 'Overheidsobligaties'. Dit impliceert dat – als het rendement van de
ene categorie boven het gemiddelde zit – het waarschijnlijk is dat bij de andere categorie het rendement eronder zit (en vice
versa). Bij een positieve relatie geeft de covariantie een positieve uitkomst te zien, bij het ontbreken van een relatie tendeert
de uitkomst naar nul.
Omdat de covariantie is uitgedrukt als verschil ten opzichte van de gemiddelden van twee waarneempopulaties, is het geen eenduidig
en makkelijk te interpreteren parameter. Daarom introduceren we het begrip 'correlatie', waarvan de vergelijking als volgt
in elkaar steekt:
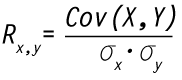
waarbij Cov(X,Y) de covariantie en σx en σy de standaarddeviaties van respectievelijk de populaties X en Y weergeven.
Resultaten
De uitkomst van de correlatie, ook wel aangeduid als de 'correlatiecoëfficiënt', zit altijd tussen de grenzen van min en plus 1.
Is sprake van een (sterk) positieve correlatie, dan tendeert de uitkomst richting plus 1, terwijl bij een (sterk) negatieve
relatie de uitkomst richting min 1 zal neigen. Is niet of nauwelijks sprake van correlatie, dan schommelt de uitkomst rond
de 0-waarde.
Omdat het teken voor de standaarddeviatie altijd positief is, is het teken van de uitkomst van de correlatiecoëfficiënt altijd
gelijk aan dat van de covariantie. Dus: een positieve covariantie leidt tot een positieve correlatie en een negatieve covariantie
tot een negatieve correlatie.
Binnen Excel maken we bij de berekening van de correlatie gebruik van de Excel-functie CORRELATIE(matrix1;matrix2).
In het werkblad Berekening covariantie voor de aandelen met hoog risico en overheidsobligaties hebben we – wederom op basis
van het werkblad Rendement en risico van diverse beleggingen – naast de covariantie ook de correlatie berekend voor de categorieën 'Aandelen met hoog risico' (kolom C) en 'Overheidsobligaties' (kolom E). In cel J41 hebben we de correlatie bepaald door invulling van de Excel-functie CORRELATIE (C2:C26; E2:E26) = -0,7708.
Er is dus sprake van negatieve correlatie tussen de rendementen van de beide categorieën! De negatieve (cor)relatie bleek
al min of meer uit de niet in fase verlopende lijnen voor de categorieën 'Aandelen met een hoog risico' en 'Overheidsobligaties'.
Nog duidelijker komt deze naar voren in het onderstaande spreidingsdiagram (als object ingesloten grafiek in het werkblad
Berekening covariantie voor de aandelen met hoog risico en overheidsobligaties; zie ook de tip hierna). In het spreidingsdiagram
is de regressielijn te zien die hierop het best aansluit volgens de methode van de 'kleinste kwadraten'. Voor de achtergrond
en de rekenregels van deze methode verwijzen wij naar de literatuur op dit terrein.
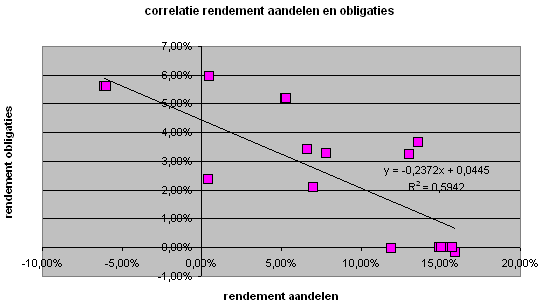
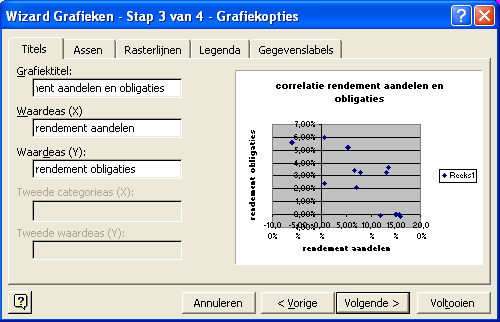
Op de x-as respectievelijk de y-as staat het rendement voor 'aandelen met een hoog risico' en het rendement voor 'overheidsobligatie'
opgenomen.
De regressievergelijking luidt Y = -0,2372X + 0,0445. De mate van (negatieve) correlatie van het spreidingsdiagram met de
regressielijn blijkt uit de correlatiecoëfficiënt R die minus 0,7708 bedraagt. Het kwadraat hiervan, ook wel aangeduid als
determinatiecoëfficiënt R2, is opgenomen in het diagram en bedraagt 0,5942. R2 is het percentage van de afhankelijke variabele (y-as) dat door de onafhankelijke variabele (x-as) in de regressievergelijking
wordt verklaard.
Praktisch gesproken betekent het voorgaande dat door diversificatie risicovermindering te behalen is.
Tips & Trucs
Spreidingsdiagram plus hierop aansluitende regressielijn maken
In deze tip sluiten we aan op de gegevens van het werkblad Berekening covariantie voor de aandelen met hoog risico en overheidsobligaties
en doorlopen vervolgens een aantal stappen om tot het spreidingsdiagram te komen.
Selecteer in het werkblad Berekening covariantie voor de aandelen met hoog risico en overheidsobligaties de reeksen C2:C26 en E2:E26 en kies de opdracht Invoegen – Grafiek.
Kies vervolgens in het venster Stap 1 van 4 voor Grafiektype – Spreiding – Volgende.
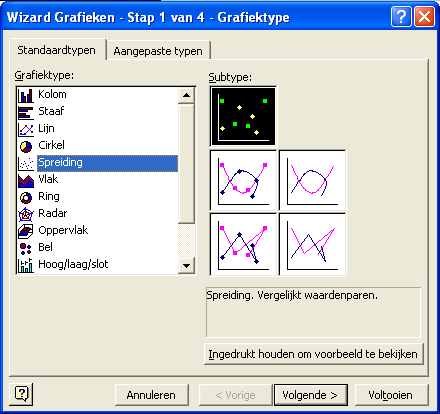
Hierna verschijnt het venster Stap 2 van 4. Bepaal hier de gegevensbron voor de grafiek op het tabblad Gegevensbereik.
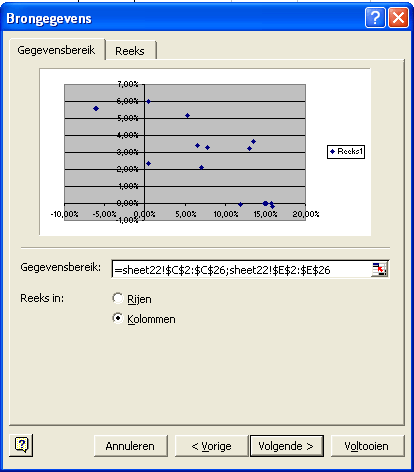
Nadat u op Volgende hebt geklikt, verschijnt het venster Stap 3 van 4. Vullen we de tekst in voor de grafiektitel, de categorieas (X) en de waardeas (Y).
Voltooi in het venster Stap 4 van 4 de wizard. Uiteindelijk verschijnt het spreidingsdiagram in de vorm van een aflopende puntenwolk in sheet 22.
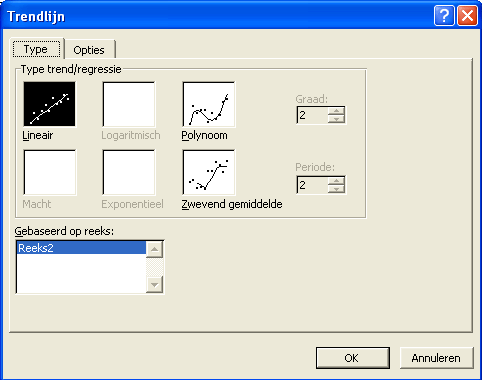
Om hier tot slot een regressielijn en determinatiecoëfficiënt aan toe te voegen gaat u naar Grafiek – Trendlijn toevoegen en maakt u de keuzes zoals hieronder weergegeven op de tabbladen Type en Opties.
 Vakinformatie
Vakinformatie 
{kind=link}

 Covariantie, correlatie en regressie bij diversificatie
Covariantie, correlatie en regressie bij diversificatie